
テキストエディタで作ったサンプルファイルでPDFのファイル形式を解説
今ごらんになっているファイル一式ダウンロードできます → pdfxhand.zip
執筆: 99/11/16 Kobu.Com
更新: 99/11/18 行末コード(追加)
更新: 99/11/23 オペレータ、圧縮方式、色について(加筆)
更新: 08/10/31 文書体裁のみ(内容は変更なし)
Acrobatで有名なPDFは、WebやCD-ROMやメールで印刷イメージの書類を配布するために使われています。 ビューアのAcrobat Readerが無償提供されていることもあり人気が出ました。
以下では、PDFファイルの中身がどうなっているか解説します。 ファイル構造、文書構造、フォントの指定方法、文字や図形や画像の表現方法など、文書交換形式であるPDFの基本仕様を、実例をあげて説明します。 しおりや注釈といった付加的機能についてはざっとしか触れません。
筆者がPDFのファイル形式を調べたときにテキストエディタで作成した、簡単なPDFファイルを説明の題材として使います。
PDFは『Portable Document Format Reference Manual』で仕様が公開されています。 また、PDFの仕様を調べるにあたっては、Adobeの技術者がSeyboldのセミナーで行った『PDF: A Look Inside』という講演内容(Webで公開)が大いに参考になりました。 また、実際のAcrobatの出力も参考にしました。
ここで説明するのはPDF文書の扱い方ではありません。 PDF文書を読むだけ、Acrobatで作成するだけの人は、必ずしもPDF形式についての知識は必要ありません。 中身がどうなっているか興味のある人、PDFファイルを生成、加工するプログラムを書こうと思っている人には参考になると思います。 ただ、ここでは基本的な事柄しか解説しませんので、詳細は『PDF Reference Manual』をご覧ください。 この解説は仕様書を読む足掛かりになると思います。
PDF(Portable Document Format)は、Adobe Systemsが開発した文書交換形式です。 コンピュータやモニタの機種、OS、搭載フォントの違いを吸収し、プラットフォームが違っても同じ体裁でページが表示できることを目指したものです。
AdobeはPDFのビューア、Acrobat Readerを無償提供しています。 Webからもダウンロードできるし、市販ソフトや雑誌付録のCD-ROMにも収められています。 特にWebで印刷形態の文書を配布する用途で普及しました。 また製品の説明書を紙ではなくPDFでCD-ROMに収めるケースも増えています。
Adobeは、PDF文書を作成するソフト、Acrobatも提供してますが、これは有料です。 Acrobatには、PostScriptファイルをPDFに変換するDistiller、アプリケーションの印刷出力を直接PDFに変換するPDFWriter、編集ソフトのAcrobat(以前はExchangeと呼んでいた)があります。 Acrobatを使うと、しおり、注釈、サムネールを付けたり、文書に暗号をかけたり、署名して改竄を禁止したりもできます。
しかしPDFは、簡単なものなら、Acrobatを用いず、テキストエディタでも作成できます。 これから、実際に手書きで作成したPDFのサンプルファイルを見ながら、PDFファイルの内部形式について解説したいと思います。
PDFの最新バージョンは1.3です。 PDF 1.3の仕様に準じて開発されたAcrobatのバージョンは4です。 最も普及したこの前のバージョン、Acrobat 3に対応するのはPDF 1.2です。
ここで説明する内容は、基本的なことだけですので、v1.2にもv1.3にもあてはまります。
PDFファイルはASCIIファイルでしょうか、バイナリファイルでしょうか。
答えは簡単ではありません。 何でもよいから手元にあるPDFファイルをテキストエディタで開いてみてください。 テキストの部分もあり、バイナリの部分もあることがわかるでしょう。 PDFの内容のうち、文書に関する情報は必ず印字可能なASCII文字で記述します。 しかし、ページに表示されるデータはASCIIでもバイナリでもよい、というのが答えです。
これからお見せするサンプルのPDFファイルは、テキストエディタによる手書きなので、全部ASCIIのテキストファイルです。 以下の説明では、サンプルファイルの各部分を切り出してお見せしますが、まず最初にファイル全体をざっと見ておいてください。
手書きサンプル → テキスト
また、実際にAcrobat Readerで表示してみてください。
手書きサンプル → PDF
たった1ページの文書です。 3行の文字列(英語と日本語)、図形が2つ(将棋の駒とたまご)、画像が1個(階段)あるはずです。
さて、それでは説明に入りますが、アプローチとして、PDFファイルを外側から内側へと順に見ていきます。
全体的に見ると、PDFファイルは、先頭部分、本体部分、末尾部分に分かれます。
%PDF-1.2 1 0 obj << /Type /Page /Parent 7 0 R /Resources 3 0 R /Contents 2 0 R >> endobj . . . 9 0 obj << /CreationDate (D:19991115) /Title (Hand-written sample PDF) /Author (ARAI Bunkichi, Yokohama Koubunsha) >> endobj xref 0 10 0000000000 65535 f 0000000012 00000 n 0000000184 00000 n 0000001672 00000 n 0000001888 00000 n 0000002185 00000 n 0000002569 00000 n 0000002992 00000 n 0000003218 00000 n 0000003324 00000 n trailer << /Root 8 0 R /Info 9 0 R /Size 10 >> startxref 3475 %%EOF
ファイルの先頭部分には % 文字で始まるコメントが書かれています。 ここではたった1行「%PDF-1.2」と書かれています。 これは、このファイルがPDFファイルであることと、準拠するPDF仕様のバージョン(ここでは1.2)を表します。
本体部分には複数のオブジェクトが定義されています。 「1 0 obj」から「endobj」までが最初のオブジェクトの定義です。 「9 0 obj」から「endobj」が最後のオブジェクトです。
オブジェクトとは、文書構造、各ページの内容、フォント定義、画像データなど、文書を構成する様々な要素です。
objの前の二つの数字はそれぞれ、オブジェクトの番号(ID)と世代番号(generation)を表します。 文書の構成要素は番号で参照するということを覚えておいてください。
オブジェクトについては後で詳しく説明します。
最後のオブジェクトに続く残りの部分がファイルの末尾です。 ファイルはコメントの「%%EOF」で終わっています。
その前の「startxref」の下の数字は、少し前の「xref」の「x」の文字の位置を、ファイルの先頭からのバイト数で示したものです。
xrefとその下の数字列が並んだ行は相互参照(cross reference)と呼ばれるものです。 ファイルの本体部分に並ぶオブジェクトをどれでも直接読み出せるようにするしかけです。
相互参照は、3列の項目が複数行並ぶ表形式になっています。 これで、特定のID番号を持つオブジェクト(の最新世代)の開始位置(id gen objのidの最初の文字の位置)がわかるようになっています。
詳細 → 相互参照
xrefとstartrefに挟まれた部分に「trailer」で始まる部分があります。 ここが実は本当の意味でのファイルの開始部分です。
後述するように、/Rootの行がカタログと呼ばれる文書の構造情報を納めたオブジェクトを指しており、/Infoの行は書類情報を納めたオブジェクトを指しています。 また、/Sizeの行はこのファイルにあるオブジェクトの個数です。
さて、以下ではPDFファイルの構成単位であるオブジェクトについて詳しく説明します。 その前に、PDFのオブジェクトを記述する基本要素について説明します。
PDFは、Adobeの印刷用ページ記述言語のPostScriptから多くを継承しています。 主に基本データ型と描画オペレータを継承しています。 しかし、PostScriptが汎用のプログラミング言語としても使えるのに対して、PDFはプログラミング言語ではありません。
詳細 → PostScriptとPDF
PDFファイルのオブジェクトを記述する基本要素です。
trueとfalseです。
かっこ (...) で囲んだASCII文字列か、比較記号 <...> で囲んだ16進数表記の文字列です。 日本語コードは通常(Shift-JISなど)印字可能なASCIIでは表現できないので、16進数表現を使います。
(Hello world) <8A4682B382F182B182F182C982BF82CD> ← 皆さんこんにちは(Shift-JIS)
つまり、日本語をそのまま読める文字で記述することはできません。
整数または実数です。
12 4.55
たいていは数値を受け付けるところなら整数でも実数でも指定できます。 整数しか指定できない場合もあります。
項目を識別するのに使います。 スラッシュ / で始まるバイト列で、各バイトは印字可能なASCII文字またはシャープ # に2桁の16進数を続けたもので書きます。
/Dog /#82l#82r#83S#83V#83b#83N ← MSゴシック(MとSは全角文字)
二番めの例はAcrobatの実際の出力例(フォントの名前)です。 2バイト文字の第1バイトだけ16進表現で、第2バイトはASCIIのまま、という妙な表記方法です。
かぎかっこ [...] に挟まれた項目の並びです。 要素のタイプは同じでなくてもかまいません。 これまで述べた基本要素のほか、以下で述べる辞書やオブジェクト参照も指定できます。 もちろん別の配列も要素にできます。
[ /Dog (Poti) 5 true ] [ [ /Tokyo (03) ] [/Osaka (06) ] ]
二重の比較記号 << ... >> の中に、キーとその値の対を並べたものです。 キーと値の対を以下では「属性」と呼ぶことにします。 キーは必ず名前です。 値はなんでもかまいません。 配列でも、別の辞書でも、次に述べるオブジェクト参照でもかまいません。
<< /Type /Dog /Name (Poti) /Age 5 /Male true >> << /Tokyo (03) /Osaka (06) >>
直前に指定されたパラメータやその時点で設定されている状態などに従い、一定の動作を実行します。
PDFのオペレータは、大半がPostScriptから継承したものですが、名前が短くなっています。 例えば、描画位置を指定するmovetoがmになるなど、すべてが1文字か2文字の英字や記号です(大文字小文字が区別されるので注意)。
以後のオペレータの説明では、カッコの中に、対応するPostScriptオペレータを示します(PDFにしかないオペレータ、動作がかなり違うものもあります)。
100 100 m 200 200 l
この例では、m(moveto)とl(lineto)がオペレータです。 まず座標系の(100,100)の位置に移動し、そこから(200,200)まで線を引きます。
obj ... endobj に挟まれたデータです。 データには何でも指定できます。 オブジェクトにはそれぞれ固有の番号(ID)と世代番号(generation)を与え、他のオブジェクトから参照できるようにします。
id gen obj . . . endobj
参照は、RオペレータでオブジェクトのIDと世代を指定して行います。
id gen R
例えば、
[ (Poti) ]
は、
1 0 obj (Poti) endobj [ 1 0 R ]
と言い換えることができます。 配列の中であってもオペレータが実行されていることに注目してください。
さて、ここまでが基本要素の説明です。
慣れる意味で、1つ例題をみてみましょう。
1 0 obj /Dog endobj 2 0 obj << /Name (Poti) /Age 5 /Male true >> endobj [ 1 0 R 2 0 R ]
オブジェクトが順に2つ定義され、最後の配列でそれが参照されています。 最初のオブジェクトは文字列、2番めのオブジェクトは辞書を含みます。 辞書には3対のキーと値が指定されています。 この結果、配列は2つの要素を持ち、次のように定義されたのと同じになります。
[ /Dog << /Name (Poti) /Age 5 /Male true >> ]
PDFの文書構造は、主に辞書を含むオブジェクトの参照関係で表現します。 文書の構造情報、個別ページの描画内容、そこに表示する画像やフォントの情報などをそれぞれ独立したオブジェクトとして定義し、互いに参照させることで、階層構造を持たせています。
また多くの場合、オブジェクトの辞書には/Typeというキーを持つ属性を定義し、そのオブジェクトのタイプを指定します。
ところで、PDFファイル内には複数のオブジェクトが定義され、それぞれに異なるIDが振られるわけですが、順序は全く関係ありません。 ファイルの先頭のオブジェクトのIDが1である必要もないし、若いIDが後ろに来てもかまいません。 IDは符丁でしかありません。
trailer << /Root 8 0 R /Info 9 0 R /Size 10 >>
先に見たように、PDFファイルの最後にはtrailerという箇所がありました。 ここには辞書( << ... >> )があり、/Root属性でオブジェクトが参照されています。 これが文書構造の頂上を示すオブジェクトです。 この場合はIDが8のオブジェクトがそれにあたります。
8 0 obj << /Type /Catalog /Pages 7 0 R >> endobj
IDが8のオブジェクトのタイプは/Catalogで、これをカタログオブジェクトと呼びます。 ここにはPages属性があり、そこからページ一覧を持つオブジェクトが参照されています。
7 0 obj << /Type /Pages /Kids [ 1 0 R ] /Count 1 /MediaBox [ 0 0 595 842 ] >> endobj
IDが7のオブジェクトのタイプは/Pages(複数)で、これがページ一覧を持つオブジェクトです。 ページ一覧は/Kids属性で指定します。 ここには、各ページを記述するページオブジェクトへの参照を順に指定します。 この文書にはページオブジェクトが1個しかなく(つまりたった1ページの文書)、それはIDが1のオブジェクトです。 /Count属性でページオブジェクトの個数、つまりこの文書のページ数がわかります。
複数ページの文書の場合、/Kids属性は次のようになります。
/Kids [1 0 R 5 0 R ... 18 0 R]
1ページめのページオブジェクトのIDが1、2ページめは5、最後のページが18になります。
/MediaBox属性はページの大きさ(印字可能範囲)を指定するものです。 属性値は4つの座標値を持つ配列で、順に、左下のX、Y座標、右上のX、Y座標です。 単位は1/72インチつまり1ポイントで、左の例の場合はA4を縦にした寸法です。
1 0 obj << /Type /Page /Parent 7 0 R /Resources 3 0 R /Contents 2 0 R >> endobj
タイプが/Page(単数)のページオブジェクトです。 /Parent属性は上位のページ一覧オブジェクトに戻れるようにするものです。 /Resources属性は、フォントなど、このページの描画で使用するリソースを指すもので、次の項で説明します。 /Contents属性で指定されるものが、ページの本体で、これをコンテンツストリームと呼びます。 リソース(フォント)の説明の後、ストリームについて説明します。
ここまでのところを整理すると、文書構造は次のように図示できます。
trailer
/Root → /Catalog
/Pages → /Pages
/Kids → /Page
/Resources → リソース
/Contents → コンテンツストリーム
ここまで述べた属性やオブジェクトは文書の骨組みを形成するものです。 PDFではこのほか、作成者や作成日など文書そのものに関する情報、しおりや注釈といった付加機能に関連した属性やオブジェクトも定義されています。
9 0 obj << /CreationDate (D:19991115) /Title (Hand-written sample PDF) /Author (ARAI Bunkichi, Yokohama Koubunsha) >> endobj
このサンプルファイルには書類情報が含まれています。 先述のとおり、書類情報は、trailerの辞書の/Info属性で参照されるオブジェクトの辞書に指定します。 これは、Acrobatの[ファイル|書類情報|一般]で表示できます。
Acrobat Readerの画面の左側に表示され、目次の働きをするしおり(outline, bookmark)は、カタログオブジェクトの/Outlines属性に指定します。 各ページに添付する注釈(annotation)は、ページオブジェクトの/Annots属性に指定します。 また、各ページのサムネール(小型表示見本)は、ページオブジェクトの/Thumb属性に指定します。
詳細はPDFの仕様書を参照してください。
リソースとは、後述するコンテンツストリーム内の描画で用いられる素材のことで、該当するページで使用するオペレータ、フォント、色空間(色の表現方法)の定義情報や、複数ページで共通に利用する画像やパターンなどです。
このサンプルのリソースオブジェクト(ページオブジェクトの/Resource属性から参照)は、使用するオペレータの種類とフォントを指定します。 色空間は、デバイス色というデフォルトのものを使うので指定を省略します。
3 0 obj << /ProcSet [ /PDF /Text ] /Font << /F1 4 0 R >> >> endobj
使用オペレータの種類は/ProcSet属性で指定します。 あらかじめ定められたオペレータのグループを表す名前を配列内に列挙します。 ここでは、基本描画オペレータ群を表す/PDFと、テキスト描画オペレータの/Textを指定しています。
/Font属性には使用するフォントを指定します。 /ProcSetのように配列ではなく、辞書の中にフォント名とフォントオブジェクトの対を指定します。 ここでは、IDが4のオブジェクトで定義されているフォントを/F1(名前は何と付けてもよい)という名前で参照することを指定します。 この/F1は後述の文字列の描画の際に出てきます。
リソースオブジェクトから参照されているフォントの定義をみてみましょう。 これは、WindowsのTrueTypeフォントの「MSゴシック」をPDFから利用できるよう定義したものです。 実際にAcrobat 4のPDFWriterが出力したものをそのままコピーして使いました。
4 0 obj << /Type /Font /Subtype /Type0 /BaseFont /#82l#82r#83S#83V#83b#83N /DescendantFonts [ 5 0 R ] /Encoding /90ms-RKSJ-H >> endobj 5 0 obj << /Type /Font /Subtype /CIDFontType2 /BaseFont /#82l#82r#83S#83V#83b#83N /WinCharSet 128 /FontDescriptor 6 0 R /CIDSystemInfo << /Registry(Adobe) /Ordering(Japan1) /Supplement 2 >> /DW 1000 /W [ 231 389 500 631 631 500 ] >> endobj 6 0 obj << /Type /FontDescriptor /FontName /#82l#82r#83S#83V#83b#83N /Flags 39 /FontBBox [ -150 -147 1100 853 ] /MissingWidth 507 /StemV 92 /StemH 92 /ItalicAngle 0 /CapHeight 853 /XHeight 597 /Ascent 853 /Descent -147 /Leading 0 /MaxWidth 1000 /AvgWidth 507 /Style << /Panose <0805020B0609000000000000> >> >> endobj
だいぶ長いですが、オブジェクトが3つ出てきます。 IDが4と5のオブジェクトは、いずれも/Typeが/Fontで、両方ともフォントそのものの定義です。 IDが6のオブジェクトは、/Typeが/FontDescriptorで、これはフォントの文字の寸法に関する情報(font metrics)を納めたものです。
最初のフォント定義(ID=4)は/Subtypeが/Type0、2番めのフォント定義(ID=5)は/Subtypeが/CIDFontType2になっています。 いずれも名前は/#82l#82r#83S#83V#83b#83Nで、これはShift-JISで読むと「MSゴシック」です(MとSは全角)。 Type 0フォントとは韓中日など文字数の多い言語のためのフォントで、コンポジットフォントと呼ばれます。 それ自体は字体の情報を含まず、別のフォントを間接的に参照します。 2番めの/CIDFontType2はTrueTypeのことで、これが字体を持つ実体フォントです。
IDが6のフォント情報オブジェクトには、幅や高さなどフォントの幾何学情報が収められています。 文書作成時に使用したフォント(この例の場合はWindows/TrueTypeのMSゴシック)の寸法に関する情報です。 PDFファイルを表示また印刷する際に、作成時のフォントがなくても、字幅などの情報をたよりに、たとえ文字の書体は違っても、同じ体裁(同じ位置に同じ字形)になることが保証されます。
詳細 → フォントについて
さて、いよいよページの本体であるコンテンツストリームについてです。 これはページオブジェクトの/Contents属性から参照されるオブジェクトです。 ストリームは、必ずオブジェクトとして定義して、Rオペレータで参照します。 IDが2のオブジェクトが、この文書唯一のページのコンテンツです。
ストリームオブジェクトは、特定ページの中身、つまり、文字、図形、画像を描画するための命令やデータを集めたものです。 このサンプルでは、3行の文字列と2つの図形、画像を1つ描きますが、これらをすべてこのストリームのデータ部分に記述します。
2 0 obj << /Length 1335 >> stream . . . endstream endobj
ストリームオブジェクトは、辞書(<< ... >>)とそれに続くデータからなります。 例のとおり/Type属性は指定しません。 実際のデータはstreamとendstreamの間に記述します。 この部分のバイト数を/Length属性で指定します。 正確にいうと、streamの後ろの改行の次の文字から、endstreamの直前の改行の前の文字までが入ります。 筆者は、テキストエディタの中でこの部分を選択し、別ファイルに書き出してサイズを調べました。
さて、ストリームの具体的な中身の説明に入る前に、座標系や色など、PDFのグラフィックスに関する基本的な事柄を整理しておきます。
PDFのページ描画モデルはPostScriptと同じです。 座標系、文字や図形の描画オペレータ、画像データの指定方法、色の指定方法など、多くをPostScriptから継承しています。
まず、文字や図形の位置や寸法を指定する座標系について簡単に説明します。
最初の座標系は各ページの描画開始時点に印字可能領域に設定されます。 印字可能領域とは先述の/MediaBoxで指定した範囲です。 原点(0,0)はページの左下、ページの右上はA4縦の場合は(595,842)です。 単位は1/72インチつまり1ポイントでした。 X座標が右方向、Y座標は上方向に増えていきます。
PDFでは文字や図形や画像の描画の際必要に応じて座標系を設定し直します。 こうして設定されている現在の座標系をCTM(Current Transformation Matrix)と呼びます。
座標系の変換操作には、原点の移動、縮尺(座標単位)の変更、回転があります。 座標の変換は6つの数で指定します。 これを変換行列(transformation matrix)と呼びます。 変換行列の詳細はPostScriptやPDFの仕様書を見てください。 ただし、回転を考えないと単純ですので、ここでは以下のサンプルファイルを理解するに足る、拡大縮小と原点移動の指定方法にしぼって説明します。
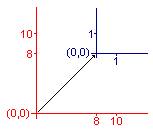
次の変換行列は、原点を(tx,ty)に移動し、x座標をsx倍、y座標をsy倍に変更するものです。
[sx 0 0 sy tx ty]
例えば、ある座標系に対して [2 0 0 2 8 8] の変換を施すと、新しい原点は元の座標系の(8,8)に移り、X座標、Y座標とも目盛りが倍の長さになります。
PDFでは、文字や図形や画像を描く色や灰色階調が指定できます。
描画の色のデフォルトは灰色階調の黒に設定されています。 灰色階調は0(黒)〜1(白)までの値を指定して変更できます。 また、RGBの3色(各色0〜1の値)で画面の表示色を指定することもできます。 さらに、CMYKの4色(それぞれ0〜1)でカラープリンタの色も指定できます。
方法は後述しますが、図形内部の塗り潰し(文字と画像の描画も含む)の染め色(fill color)と、線画のなぞり書きで使うペンの色(stroke color)は別々に設定します。
このサンプルでは灰色階調とRGB色を使ってみます。
詳細 → 色について
さて、PDFの座標系や色についてわかったところで、順にストリーム内の文字、図形、画像を描画する命令を見ていきます。
まず文字の描画です。 サンプルには次の3行が表示されています。 フォントは表示のとおりMSゴシック24ポイントを使います。
Hello World MSゴシック24ポイント それを灰色にしたもの
streamとendstreamの囲まれたページ描画命令の最初の部分です。
BT /F1 24 Tf 1 0 0 1 72 648 Tm (Hello World) Tj 1 0 0 1 72 612 Tm <4D53835383568362834E3234837C834383938367> Tj 1 0 0 1 72 576 Tm 0.5 g <82BB82EA82F08A44904682C982B582BD82E082CC> Tj ET
BT(Begin Text)とET(End Text)に挟まれた部分が描画するテキストの指定です。 一連の描画オペレータ群をBTとETで囲むのは、PDFファイルからテキスト部分だけを順序よく取り出すことができるようにするためです。
Tf(Text font、PostScriptのsetfontにあたる)で使用するフォントを指定します。 ここでは、リソースオブジェクトで定義済みのフォントの名前(/F1)とフォントサイズ(24ポイント)を指定します。
Tm(Text matrix)で印字する最初の文字の左横に原点が来るよう座標系を変更します。 ここではページの左端から1インチ(tx = 72)、上から3/2程度(ty = 626)の位置です。 縮尺は変えません(sx = sy = 1)。
文字列を指定して、Tj(show)で印字します。 先述のとおり、文字列は (印字可能ASCII) または <16進数> という表記で指定します。 最初の文字列は「Hello World」です。 以下、順に1/2インチずつ下にずらしながら(Tmでtyを36ずつ減らす)、「MSゴシック24ポイント」と「それを灰色にしたもの」を印字します。
文字の色はデフォルトで黒ですが、色の指定もできます。 ここでは、3番めの文字列を灰色階調で描画しています。 g(setgray)で0.5、つまりちょうど半分の濃さを指定します。
次は図形の描画です。 このサンプルではふたつの図形を描いてみます。 直線と曲線を使って、塗り潰しとなぞり書きを試してみます。
PDFにはPostScriptの描画オペレータのうち基本的なものが備わっています。 座標位置を指定しながら、一筆書きのように直線や曲線を組み合わせてパスを描き、最後に内部を一定の色で染める(fill)ことも、線の部分を一定の色、一定の太さのペンでなぞる(stroke)こともできます。
曲線はIllustratorでおなじみのベジエ曲線を使います。 各曲線の出発点と到着点のほか、それぞれの方向と強さを指定する制御点を指定します。 まず、ページ中央左側に全面青の将棋の駒を、その右側に赤枠の卵を立てたものを描いてみます。
最初は将棋のコマです。
q 12 0 0 12 72 360 cm 0 0 0.5 rg 0 0 m 12 0 l 10 11 l 6 12 l 2 11 l f Q
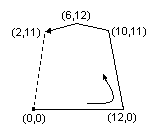
まず、cm(concat)で、座標系を (72,360) に移し、座標単位を縦横同じく12(ポイント)に設定します。 つまり、ページの左端から1インチ、下から5インチのところを原点にし、1目盛りを1/6インチに変更します。
さて、cmの前の行でq(gsave)というオペレータを使っています。 これは最後のQ(grestore)と対になるもので、座標系や描画パラメータなど描画状態(graphics state)を変更する前に、以前の状態を一時保存し、描画が済んだら元に戻すという操作を行うものです。
rg(setrgbcolor)でRGB色を指定します。 ここでは [0 0 0.5] つまり暗い青を指定します。
ここからが作図作業です。 m(moveto)で図形の開始点、ここでは新座標系の原点に移動します。 そこからl(lineto)で座標系に仮想の直線を順に描き、パスを作ります。 まず底辺、次に右の辺、右上の斜め線、左の斜め線までを描きます。 最後の左の辺は不要です。パスは自動的に閉じられます。 いよいよf(fill)で内部を現在指定されている色、つまり青で染めます。
次は赤い線の縦置きのたまごです。
q .5 w 12 0 0 12 360 360 cm 0.5 0 0 RG 0 0 m 8 0 4 12 0 12 c -4 12 -8 0 0 0 c S Q
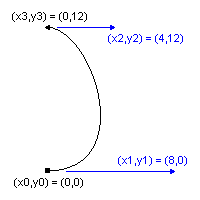
座標の設定(cm)、描画状態の保存(q)と復元(Q)は駒を描いたときと同様です。 座標単位は同じ12ポイントですが、X座標だけ駒の右側にずらしました。
w(setlinewidth)でなぞる線の太さを指定します。 0.5単位、つまり6ポイントの太さです。
RGでRGB色を指定します。 rgとRGは、それぞれ塗り潰し(fill)用と線画(stroke)で使う色を指定します(文字の描画はfillにあたり、rgで指定された色が使われます)。 このように、描画状態を指定するオペレータは、大文字がfill用、小文字はstroke用に分けられています。 PostScriptにはこのような区別はありません。
作図に入ります。 まず、m(moveto)で出発点に移動します。 新座標系の原点です。 続いてc(curveto)で曲線を描きます。 2つのcオペレータで、まず楕円の右半分を上に向かって、次に左半分を下に向かって描き、パスを構成します。 最後にs(stroke)で作ったパスを印刻します。
ベジエ曲線を描くcオペレータは、6つのパラメータを取ります。
x1 y1 x2 y2 x3 y3 c
これは3組のXY座標値です。 曲線の始点は現在位置で、これを(x0,y0)とします。 曲線は、(x0,y0)から始まり、(x3,y3)で終わります。 (x1,y1)と(x2,y2)がそれぞれ始点と終点の制御点です。 つまり、出発時の曲線の方向と強さは(x0,y0)から(x1,y1)へ向かうベクトルで、到着時の方向と強さは(x2,y2)から(x3,y3)へのベクトルで表されます。
PDFではカラーまたは灰色階調とモノクロのビットマップ画像を描画できます。
ここではマスクと呼ばれる特別なモノクロ画像を表示してみます。 これはあるピクセルを描くか透明にするかを示すビットマップです。 別の画像と重ねて縁取りをしたり、中をくりぬいたりするのに使いますが、単独で任意の色を持つ1色刷りの画像としても使えます。
カラーまたは灰色階調の画像の表示方法も画像マスクとほぼ同様ですが、ピクセルあたりの色数やビット数を指定します(マスクの場合は常にピクセルあたり1ビット)。
0 0.5 0 rg 144 0 0 144 72 144 cm BI /W 16 /H 16 /BPC 1 /F /AHx /IM true ID 0FFF 0FFF 0FFF 0FFF 00FF 00FF 00FF 00FF 000F 000F 000F 000F 0000 0000 0000 0000> EI
画像は、BI(Begin Image)、画像属性、ID(Image Data)、サンプルデータ、EI(End Image)という形式で指定します。
BIとIDの間には辞書形式と同じ、キーと値の対を複数指定します。 /IM(ImageMask)はこれが画像マスクであることを表します。 つまり、ピクセルあたりのビット数(/BPC = BitsPerComponents)は必ず1ビットです。 幅(/W = /Width)16ビット、高さ(/H = /Height)16ビットです。 ですから、画像データは、16 × 16 × 1 ÷ 8 = 32 バイトになります。
/F(/Filter)はデータ部分のエンコード方法を示し、ここでは単純な16進数表示(/AHx = /ASCIIHexDecode)を使います。 1バイトを16進数2桁で表現します。データの終わりには「>」を付けます。 ほかに、圧縮をかけてから、ASCII表現にするなど任意のフィルタが使用できます。 圧縮方式とASCII変換についてはこのすぐ後で述べます。
IDからEIまでがデータ部分です。 1行に2バイト、つまり横一列の16ビット分が並びます。 これが16行あります。 これもやはり「手書き」の画像で、左上がりの階段です。
BIの前では、rgで色が指定されています。 [0 0.5 0]ですから濃い緑です。 データビットの0がこの色で、1が背景の白で描かれます。
次のCm(concat)オペレータにより、ページの左端から1インチ、下から2インチの位置に画像が表示されます。 さて、縮尺のほうですが、PDFでは、画像データはどんな大きさでも常に、幅も高さも1単位と決まっています。 Cmで設定した座標系の単位は144ポイント、つまり2インチです。 ですから、幅も高さも、16ピクセル → 1単位 → 144ポイントという倍率変換が行われ、画像の1ピクセルは9(144/16)ポイントになります。
PDFファイルの中心部分である、文字や図形や画像の描画方法を見てみました。
さて、このサンプルでは、文字の図形の描画はもともとASCII表現なので圧縮せずそのまま、画像データも圧縮せず単純なASCIIの16進数表現を用いて表記しました。 そこで最後に、PDFファイルのデータ部分のエンコード方法について簡単に触れておしまいにします。
画像データのところで見たように、PDFでは、データ部分をエンコードした場合は、そのデコード方法を/Filter属性で示します。
エンコード方式には、圧縮方式のLZW、ZIP、JPEG、FAXなどがあります。 また、そのままメールで送れるようバイナリデータを7ビットASCIIに変換する方式もあります。
詳細 → 圧縮方式とASCII変換
PDFでは、データの種類によってエンコード方法が変えられるようになっています。 また、圧縮をかけてからASCII変換を施すなど、複数のエンコード方式を指定することも可能です。
さて、PDFは文書交換を目的としているので、圧縮してサイズを小さくしたり、ASCIIに変換してメールで送れるようにするのは納得できます。 しかし、ファイル全体をひとつのエンコード方式で変換するのではなく、ストリームデータだけをそれぞれ選択的に、異なるエンコード方法で変換するのはなぜでしょうか。
それはすぐに最初のページを表示できるようにするためです。 まず全体を解凍してから特定部分を見つけるのではなく、表示したいページを見つけてから、表示の際にその部分だけ解凍できるようにしているのです。
これで手書きPDF入門の説明を終わります。
このページの残りの部分は、上記の本文からも参照されている個別項目の説明です。 PostScriptとの違い、フォントや色、相互参照や圧縮方式、Acrobat SDKなどの補足説明です。 最後に参考文献をまとめまてあります。
PDFとPostScript
フォントについて
色について
圧縮方式とASCII変換
相互参照
行末コード
Acrobat SDK
参考文献
PostScriptはグラフィックス機能を備えた汎用のプログラミング言語です。 PDFもPostScriptと同様のグラフィックス機能を備えていますが、汎用と言えるプログラミング機能はありません。 PDFは、PostScriptやEncapsulated PostScriptを土台に設計されました。 その際、過去の反省が盛り込まれました。
『PDF: A Look Inside』によれば、プリンタの描画エンジンとして大成功を納めたPostScriptですが、問題もあったといいます。 それは、PostScriptの文書は自由に記述が可能なプログラムであるという性質に起因するものです。 プログラムのエラーのため印刷できない文書が少なからずあることです。
PostScriptプリンタをお使いの人なら、Webからダウンロードした文書をプリンタに打ち出すと、「PostScript Error」ページが一枚出て、それでおしまいという経験が一度くらいはあると思います。 中身が複雑なプログラムであるため、こうなると手の施しようがありません。 たとえPostScriptがペラペラの人でも他人(のプログラム)の出力を解析する気にはなれないと思います。
PostScriptの特徴のひとつである、単なるページ記述データ形式を超えた、自由なプログラミング言語であるという柔軟性が実は諸刃の剣だったわけです。
PDFでは、この反省を踏まえて、データ表現と描画オペレータ以外のオペレータをなくすことでプログラミング機能を制限し、また、文書形式に一定の規則を設けることで、エラー発生の可能性を少なくしました。
PostScriptとPDFでは、文書内のページの独立性の度合いも異なります。 PostScriptでは、showpageでページ出力を指示する以外、文書内の各ページに特に区切りはありません。文書全体を通して一定の状態が保持されたり、特定の数ページの出力中だけ特殊な状態が継続する、などということがありえます。 このため、文書内の特定ページを抜き出して印刷することが原理的にむずかしかったのです。
Illustratorの図の出力形式として使われているEncapsulated PostScript(EPS)は、もともと図とはかぎらず、1ページ分のPostScript言語プログラムを独立ファイルに納めるための仕様でした。 しかし、EPSページの出力でさえ、取り込まれたPostScriptプログラムの状態に影響を受けます。
PDFでは、各ページごとにあらゆる描画状態が初期状態にリセットされるようになりました。 このため、全ページに渡る共通の描画パラメータがある場合でも、毎回設定しなければなりません。 しかし、こうしたおかげで、途中のページをすばやく確実に表示できるようになりました。
PostScriptでは基本的には文字数が256文字までのフォント(ベースフォントと呼ばれる)が本来のフォントであり、これより文字数が多い韓中日などのフォントは例外的な扱いになっています。 コンポジットフォントというものが設けられ、そこから複数の256文字ずつに分かれた部分フォントを束ねる二段階方式になっています。
Adobeは近年、字数制限のないTrueTypeをサポートしたり、CID(Character Identifier)フォントと呼ぶ、字数制限のないフォント形式を定めましたが、PDFでは、英字フォントと日本語フォントの扱いはいまだに異なります。 サンプルで見たとおり、韓中日フォントは、たとえ目的のフォントがTrueTypeでも、コンポジットフォントを介して間接参照するようになっています。
PDFは、ファイル内部に使用フォントの寸法情報を持つようになりました。 フォントの字形情報の全部または一部を埋め込む機能もあります。 PostScriptは、表示/印刷装置の解像度への依存度をなくしましたが、搭載フォントの違いは吸収できませんでした。 PDFでは、作成時のフォントの寸法情報を保持し、出力時は代替フォントを使うことで、これを吸収しました。
PDFの色の表現方法には、表示/印刷装置の設定の色のまま出力する方法(デバイス色)、発色装置の特性を考慮して正しい色に直して出力する方法(デバイス独立色)、そのほか特殊な表現方法があります。 このような各種の色の表現方法を色空間(color space)と呼びます。 色を表す数値は0.0〜1.0の範囲で指定します。
デバイス色には次のものがあります。
| 色空間 | 説明 |
|---|---|
| DeviceGray | 灰色階調 |
| DeviceRGB | 画面の光点の強さを赤緑青3原色で表す |
| DeviceCMYK | 印刷で藍紅黄墨4色インクの量を表す |
デバイス独立色には次のものがあります。
| 色空間 | 説明 |
|---|---|
| CalGray | 灰色階調を補正 |
| CalRGB | RGB色を補正 |
| Lab | L*/a*/b*という3つの値で色を指定 |
| ICCBased | ICC(International Color Consortium)という機関が定めたプロファイルを使用 |
特殊表現には次のものがあります。
| 色空間 | 説明 |
|---|---|
| Separation | 印刷でインクの色ごとの版を作るために使用 |
| DeviceN | 印刷で蛍光色など特殊インクの版を作るために使用 |
| Indexed | 画像の描画で、色値を直接指定せず、パレットに納めた色のインデックス値で指定 |
| Pattern | タイルや網掛けを指定 |
PDFで色を指定する正式な方法は、まず色空間を選んで、その中で特定の色を示す値を選ぶ手順を取りますが、デバイス色の場合は、いきなり具体的な色や灰色階調の値を選ぶことができます。 このサンプルでは後者の方法でDeviceGray空間とDeviceRGB空間の値を指定しました。
PDF文書は、文書の構造や属性を指定する部分は常にASCII文字で、実際にページに表示される構成要素となるデータには内容に合った圧縮方式とASCII変換を施す、と説明しました。
PDFの仕様では、圧縮をかけるかどうか、どの圧縮方式を選ぶか、さらにASCII変換を施すかどうかを、文書内の各要素ごとに変更できるようになっています。 Acrobatで作成する場合は、データの種類ごとにユーザが選択するようになっています。
PDFで選択可能な圧縮方式には次のものがあります。
| 圧縮方式 | 説明 | 用途 |
|---|---|---|
| LZWDecode | Lempel-Ziv-Welch方式 | テキスト/合成画像 |
| RunLengthDecode | 繰り返しを除去 | 合成画像 |
| CCITTFaxDecode | ファクシミリ方式(CCITT Group 3/Group 4) | モノクロ画像 |
| DCTDecode | JPEG方式 | 写真画像 |
| FlateDecode | ZLIB/DEFLATE方式(ZIP) | テキスト/合成画像 |
このうち、LZWDecodeとFlateDecodeは、原理も性能も用途も似たようなもので、代替可能です。 PostScriptでは当初、Unisysが特許を持つLZWがだけがサポートされていました。 パブリックドメインのZIPが追加されたのは後からです。
LZWは、CompuServeが仕様を公開し、誰でも自由に使ってよいとしたGIFで使われている圧縮方式です。 ところが、途中からUnisysが特許使用料を請求するようになり、しかもライセンス条件が不明瞭かつ一定していません。 ZIPが追加されたのはこうした事情からだと思います。 ZIPは、RFC1950/1951で仕様が公開されており、誰でも自由に使用できます。
ASCII変換は、圧縮とは逆にデータが増えます。 圧縮済みのデータは通常バイナリデータなので、例えば、7ビットデータの通過しか保証されていないインターネットメールにそのまま送出することはできません。 そこで、7ビットASCIIに変換してから送ります。
PDFは2つのASCII変換方式をサポートしています。
| 変換方式 | 説明 | 性能 |
|---|---|---|
| ASCIIHexDecode | 1バイトを16進数2桁で表現 | サイズは2倍 |
| ASCII85Decode | 印字可能部分の85文字を使うもの | 4バイトが5バイト、つまり25%増し |
インターネットメールの標準ASCII変換方式のBASE64(3バイトが4バイト、つまり33%増し)はサポートされていません。
WebやCD-ROMでしか配布しないのであればASCII変換の必要はありません。 また、メールで送る場合でも、BASE64を施して添付すれば問題ありません。
PDFの仕様書はWebで公開されていますが、518ページもあるPDFファイルです。 PostScriptの仕様書のPDFファイルも同じく公開されており、こちらは912ページもあります。 これを開いてみると、一瞬にして最初のページが画面に表示されます。 どこか別のページに飛んでみると、そこがただちに表示されます。
相互参照(cross reference)は、巨大な文書のなかから特定のページやそこに表示する画像を探しやすくして、表示速度を上げるためのしくみです。 また、一時にファイル全体をメモリにロードする必要がなく、メモリの少ないマシンでも大きな文書を開くことができます。 さらに、ファイルを変更する場合は、既存部分を一切変更せず、ファイルの末尾に新しいデータを追加し、更新後の相互参照を生成して追加します。
「相互参照」とはいうものの、ここから一方的にファイル内のオブジェクトに至るだけの用途で使われます。
xref 0 9 0000000000 65535 f 0000000012 00000 n 0000000184 00000 n 0000001672 00000 n 0000001888 00000 n 0000002185 00000 n 0000002569 00000 n 0000002992 00000 n 0000003218 00000 n trailer << /Root 8 0 R /Size 9 >> startxref 3324 %%EOF
相互参照には、ファイル内の全オブジェクトの位置情報をID順に並べます。
本文でも述べたように、相互参照の位置はstartxrefで示します。 また、trailerの/Size属性で相互参照の項目数(参照オブジェクトの個数)を指定します。
相互参照の先頭行のxrefの下の行には2つ数字が並んでいます。 最初の数字は、先頭の位置情報のオブジェクトIDで、この場合は0です。 オブジェクトの0は使いません。 2番めの数字は行数、つまり列挙されたオブジェクトの個数で、ここではIDの0〜8までの9個です。 オブジェクトの位置情報は番号順に並びます。 各行の最初の数字は各オブジェクトの定義位置のid gen objのidの最初の文字の位置を指しています。 次の数字は世代番号、最後の文字はfが未使用、nが使用中を表します。
仕様書には相互参照が省略可能とは書かれていません。 しかし、相互参照のないファイルをAcrobatで開いてみると、ファイルが壊れているとの警告は出るものの、読み込んで表示してくれます。
筆者は、16進ダンププログラムでファイルの内容と位置を表示して相互参照の表を作成しました。
テキストファイルの行区切りはプラットフォームによって異なります。 Macintoshは復帰文字(CR)1文字、UNIXは改行文字(LF)1文字、Windowsや、インターネットの標準形式はCRとLFが続く2文字です。
PDFではどの行末コードも認められています。どのプラットフォームでもファイルをそのまま開くことができるよう設計されています。
Acrobatの実際の出力を見るとMacintosh形式のCRが使われているようです。 場所によっては、CRの前に余分な空白が1文字置かれており、ファイル内の位置を変えずに行末コードが変更できるようになっています(独特のやりかたですね)。
この手書きサンプルはWindows環境で作成したもので、行末コードはCR-LFにしてあります。 しかし同じファイルを、Windowsだけでなく、MacintoshのAcrobat Readerでもそのまま開くことができます。
PDFがプラットフォームに依存しないファイル形式であるのは、文書交換形式であれば当然かもしれません。しかし、PDFの登場前から単一ページのページ記述形式として利用されているEncapsulated PostScript(EPS)は、MacintoshとWindowsで形式が異なり、一般には一方の環境で作成したファイルをもう一方の環境で読むことはできませんでした。
サードパーティが、PDFファイルを作成したり、読んだり、加工したりするプログラムを作ることはできるでしょうか。
PDFは仕様が公開されており、PDFファイルを操作するプログラムを作成することは可能ですし、Adobeも認めています。 手書きサンプルで試したように、新規にPDFファイルを作成するのはそれほどむずかしくはありません。
しかし、ライセンスの問題があるため、既存のファイルを読み込んだり、加工して書き出すのは簡単ではないでしょう。 PDFファイルで用いられている圧縮方式の一部、暗号方式、署名機能のプログラミングには、他社のライセンスが必要です。 LZWはUnisys、暗号や署名はRSAからライセンスを受けないと使用できません。
このためかAdobeは、Acrobatの機能を外部のプログラムから利用するためのAPIを公開しています。 Acrobatが利用できる環境であれば、その力を借りてPDF文書を読んだり、加工するプログラムが作成できます。 Adobeはすでに上記のライセンスを受けてAcrobatを開発しているわけで、サードパーティが、直接こうしたライセンスを受けたり、PDFファイルを自ら解読せずに、PDFファイルを操作できるようになっています。
Acrobat APIを利用するための開発キット、Acrobat SDKはWebで無償提供されています。 これはAcrobatのAPIを解説したもので、サンプルやユーティリティも付属しています。 ただし、AcrobatのAPIを使ってプラグイン(Acrobat Readerに機能を追加するDLL)を開発する場合は、Adobeとライセンス契約を結ぶ必要があります。
Acrobat SDKのほかに、有償のPDFライブラリというのがあります。 これは、AcrobatなしでPDFの生成、読み込み、加工を行うことができるものです。
筆者はAcrobat SDKもPDFライブラリも試したことはありません。 機会があれば、Acrobat SDKは試してみたいと思っています。
PDF、Acrobat、PostScriptの情報はAdobe SystemsのWebサイトにあります。
また、技術者向け資料は「テクノート」として公開されています。
このうち、手書きPDFの作成で参照した基本資料は次のものです。
Adobeの技術者によるSeyboldセミナーの講演記録です。 印刷の入稿形式としてPDFが使えないかという議論もされています。

制作: Kobu.Com
提供: Kobu.Com (Kobu.Com)
公開するサンプルは試作品で、完全なものではありません。
この解説書とサンプルの転載はご遠慮ください。
リンク張りは歓迎いたします。
ご意見ご感想お問合せも歓迎いたします。
Copyright (c) 1999 Kobu.Com. All rights reserved.